Anthropic lanza Claude Opus 4.5, el primer modelo que ataca problemas reales de los agentes LLM en producción: saturación de contexto, ping-pong infinito, JSON frágil y costes elevados.
Anthropic acaba de lanzar Claude Opus 4.5, y por primera vez en mucho tiempo veo un modelo que no solo promete ser más inteligente, sino que ataca problemas reales de los que sufrimos cuando intentamos meter LLMs en producción. Especialmente en sistemas agentic.
El problema real: Los agentes actuales son ineficientes
Si has intentado construir algo más complejo que un chatbot, sabrás que los agentes LLM tienen problemas serios:
1. Saturación de contexto: Le pasas al modelo la documentación de 50 herramientas disponibles (GitHub, Notion, Slack, JIRA…) y medio contexto se va en listar APIs que igual ni usa.
2. Ping-pong infinito: El modelo llama una tool, esperas respuesta, vuelves a llamar al modelo con el resultado, llama otra tool… En tareas largas esto es brutal en latencia y coste.
3. JSON frágil: La comunicación modelo-app vía tool calling es propensa a errores. Un JSON mal formado y se te cae el workflow.
4. Coste por las nubes: Modelos potentes gastan tokens como si no hubiera mañana. Una tarea de desarrollo puede consumir cientos de miles de tokens fácilmente.
Opus 4.5 ataca estos cuatro problemas de frente.
Tool Search Tool: Carga herramientas bajo demanda
En lugar de meter todas las herramientas en el contexto inicial, Opus 4.5 introduce Tool Search Tool.
El modelo puede buscar y cargar la documentación de herramientas solo cuando las necesita. ¿Trabajando con un repo de GitHub? Carga la API de GitHub. ¿Necesitas crear un ticket en JIRA? Carga JIRA en ese momento.
¿Por qué esto importa?
Menos tokens desperdiciados, contexto más limpio y enfocado, y escalabilidad: puedes tener cientos de tools disponibles sin saturar el prompt. Para quienes hemos lidiado con sistemas con decenas de integraciones (APIs de billing, ERPs, CRMs…), esto es oro.
Programmatic Tool Calling: Adiós al ping-pong
Aquí está la jugada más interesante: en lugar de que el modelo llame una tool, espere respuesta, y vuelva a procesar, Opus 4.5 introduce una capa intermedia de ejecución de código.
El modelo genera código que:
- Ejecuta múltiples llamadas a tools secuencialmente
- Procesa los resultados
- Toma decisiones basadas en esos resultados
- Coordina el workflow completo
Todo sin tener que hacer round-trips constantes con el modelo.
Ejemplo práctico
Imagina que estás construyendo un agente que revisa PRs en GitHub. En lugar de:
- Llamar a get_pr_details
- Esperar respuesta
- Llamar al modelo
- Llamar a get_pr_diff
- Esperar respuesta
- Llamar al modelo…
El modelo genera código que hace todas las llamadas necesarias, procesa los datos y solo te devuelve el resultado final.
Impacto
Latencia reducida drásticamente, menos llamadas al modelo = menos coste, y el contexto se mantiene mejor en tareas largas. Esto es especialmente brutal para workflows complejos tipo CI/CD, análisis de datos multi-paso, o automatizaciones empresariales.
Eficiencia: 65% menos tokens
Anthropic dice que Opus 4.5 usa hasta un 65% menos de tokens para completar la misma tarea que sus modelos anteriores.
¿Qué significa esto en la práctica?
Sí, el precio nominal es $5 entrada / $25 salida por millón de tokens. Parece caro. Pero si usas 65% menos tokens, el coste real por tarea se desploma.
Ejemplo de ahorro en costes
| Modelo | Tokens usados | Coste estimado |
|---|---|---|
| Opus 4 | 100k tokens | $2.50 |
| Opus 4.5 | 35k tokens | $0.875 |
No estás pagando más por millón de tokens, estás pagando mucho menos por resultado útil.
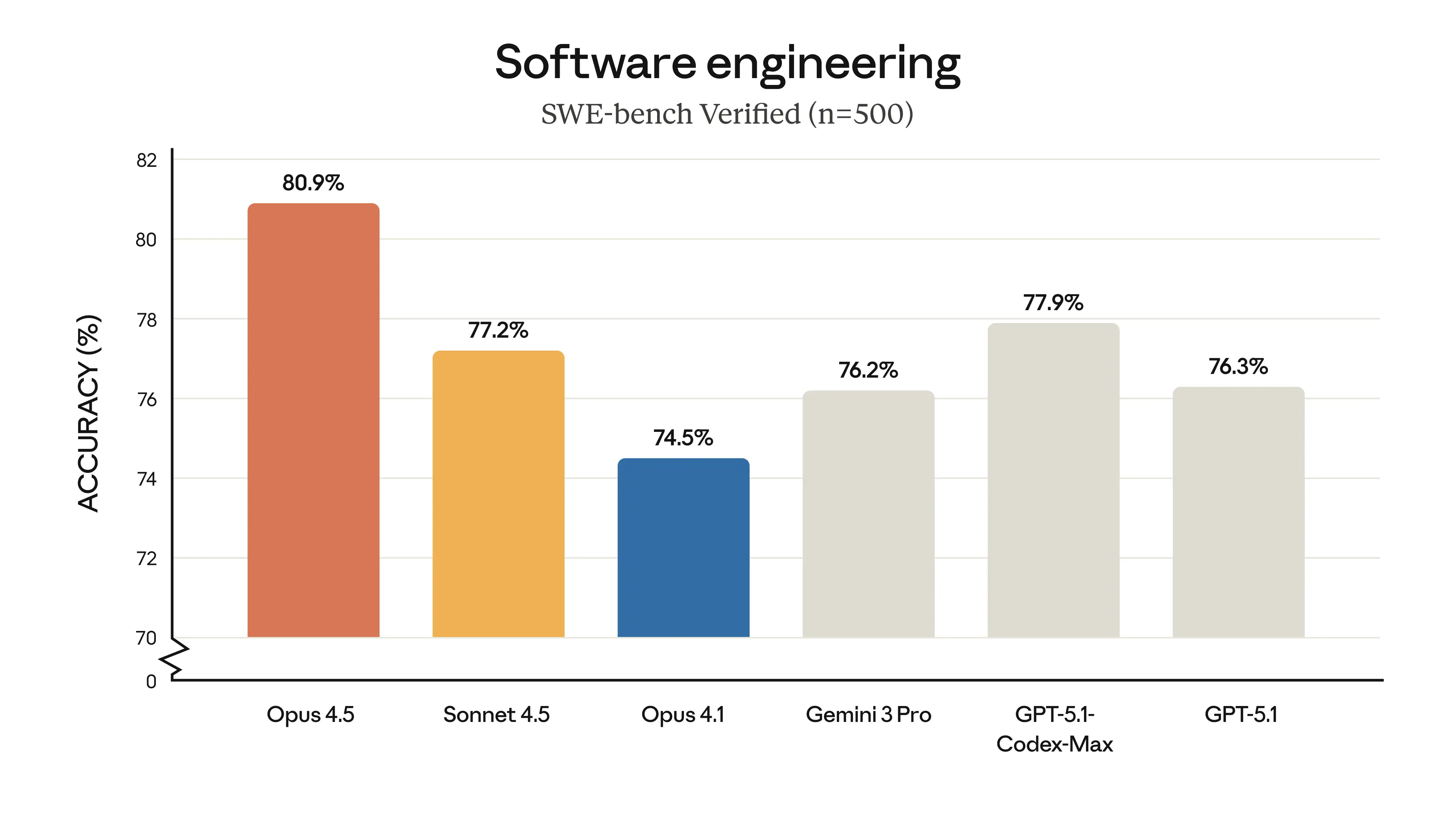
Y encima, Opus 4.5 saca la mejor puntuación en SWE-Bench verificado (el benchmark de código serio, no el inflado). O sea, no es eficiencia a costa de calidad.
Video explicativo
Análisis en profundidad sobre las capacidades de Claude Opus 4.5 y su impacto en el desarrollo de agentes
Patrones mejorados de integración
Anthropic también está puliendo los patrones de tool use: mejores estructuras de JSON, manejo de errores más robusto, ejemplos de cómo estructurar la comunicación entre modelo y aplicación agentic.
Si has trabajado con tool calling en GPT-4 o Claude anterior, sabes que es complicado mantener esos workflows estables. Cualquier cambio en el schema de las tools y te toca revisar todo.
Los nuevos patrones prometen hacer esto más mantenible.
¿Por qué esto importa ahora?
Porque llevamos dos años oyendo promesas de agentes autónomos que en producción se caen a la primera de cambio.
Los casos de uso reales de agentes (desarrollo de software, análisis de datos, automatización empresarial) requieren:
- Llamadas a múltiples sistemas
- Workflows de varios pasos
- Manejo de errores robusto
- Eficiencia de coste
Opus 4.5 es el primer modelo que veo atacando estos problemas de forma sistemática, no solo mejorando el razonamiento en abstracto.
Casos de uso que tienen sentido ahora
Con estas mejoras, hay escenarios que empiezan a ser viables:
- Code review automatizado: Analizar PRs, correr tests, sugerir cambios, actualizar documentación. Todo en un solo workflow.
- Análisis de datos multi-fuente: Conectar a PostgreSQL, APIs externas, procesar, generar dashboards. Sin intervención manual.
- Automatización de operaciones: Desde gestión de incidencias hasta despliegues. El agente coordina múltiples herramientas DevOps.
- Asistentes empresariales avanzados: No solo buscar info, sino ejecutar acciones (crear tickets, actualizar CRMs, generar reportes…).
Son cosas que técnicamente ya se podían hacer, pero el coste y la fragilidad los hacían inviables. Esto cambia la ecuación.
Mi conclusión
Después de años viendo modelos que mejoran en benchmarks pero siguen siendo un dolor en producción, Opus 4.5 me parece el primer paso serio hacia agentes que realmente escalan.
No es AGI ni nada por el estilo. Es ingeniería de sistemas aplicada a LLMs: optimizar contexto, reducir latencia, mejorar robustez.
Y eso, honestamente, es lo que necesitamos.
Si estás construyendo algo con agentes, o lo has intentado y te has frustrado con las limitaciones actuales, este modelo merece la pena probarlo.
¿Qué opinas?
¿Habéis experimentado con agentes en producción? ¿Cuáles han sido vuestros principales dolores de cabeza?

